
Unpatched vulnerabilities are perhaps the greatest single threat to any organization's security. That's why it's absolutely essential to track CVEs, map those to your environment, and quickly remediate them everywhere they exist.
But if you're part of a SecOps team at a large organization, you're being asked to do the impossible. The total number of assets dispersed across the environment you're tasked with protecting probably reaches into the hundreds of thousands. Given the continued growth in CVEs, the number of vulnerabilities you discover by scanning those assets probably reaches into the millions, not to mention the web vulnerabilities you have to look after as well. So you can't possibly patch all the vulnerabilities in your environment before more new ones crop up.
To make matters worse, we live in a work-from-anywhere world, where organizations are more spread out than ever. The size of your organization makes it an especially attractive target for cybermaliciousness. So a swarm of threat actors are likely probing your environment at this very moment looking for one of your unpatched vulnerabilities.
The complexity of network environments, compounded by the increasing number of vulnerabilities, dramatically increases your chances of being breached. The only question is how soon—and how bad.
What we do now isn't working
If you're a cybersecurity professional working at one of these organizations, you have a few options:
Option #1: General best effort.
Some SecOps teams respond to the overwhelming volume of vulnerabilities in their environment by doing the best they can. Sometimes they'll focus their efforts on a vulnerability that "feels" important because it affects a particularly valuable asset. Other times, they'll focus on a vulnerability that has a high number of instances—since that seems like an efficient way to work.
The problem with this approach is that it doesn't appropriately prioritize the vulnerabilities that objectively pose the greatest risk to the organization. So while it may seem "efficient" to spend 48 hours clearing the 10,000 vulnerabilities created by just a handful of just-published CVEs, doing so may problematically leave your entire organization unnecessarily exposed to an existential risk for two entire days due to a single, unremediated vulnerability that's more dangerous than all 10,000 of the other aforementioned vulnerabilities combined.
Option #2: Use CVSS severity ratings.
CVEs come with severity ratings (CVSS). Many organizations use these ratings to prioritize their patching and remediation work. In fact, use of CVSS ratings is recommended—and even mandated—by various industry standards and government agencies.
Unfortunately, this approach isn't especially useful either. For one thing, CVSS scores are calculated intrinsically. That is, they are not put in the context of your organization's particular characteristics: the role a given type of asset plays in your infrastructure, the dollars at risk if a specific system were to be brought down, the regulatory implications of a compromise in a particular system, etc.
For another, while CVSS scores theoretically offer 101 different values (0.0 to 10.0), in practice just six scores make up 67% of all vulnerabilities in the National Vulnerability Database (NVD). And when organizations extract the vulnerabilities relevant to their environment from the NVD, the "clumping" gets even worse (see chart). Practically speaking, you can't effectively prioritize millions of vulnerabilities with just five priority levels. After all, Southwest Airlines uses three boarding groups to seat a mere 180 passengers!
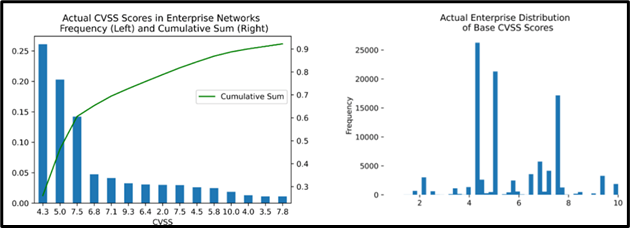
Baseline CVSS ratings alone do not give SecOps teams at large organizations the insight they need to appropriately prioritize the millions of vulnerabilities in their environments.
Option #3: Enhance CVSS ratings with context.
SecOps teams can theoretically give appropriate context to baseline CVSS numbers by applying what are under CVSS terminology referred to as "temporal" and "environmental" factors.
Unfortunately, studies show that SecOps teams can't reliably apply CVSS's supplementary metrics to produce risk ratings worthy of trust. Ratings are especially unreliable when they involve system vulnerabilities on segmented networks—i.e., the type of vulnerabilities that often pose the greatest risk to large organizations. A study done by the Delft University of Technology revealed that the accuracy with which SecOps professionals risk-rated vulnerabilities dropped from 83% in flat networks to 59% in the kind of segmented networks that characterize larger organizations.
And in the same study when it came to system vulnerabilities (as opposed to application vulnerabilities) in segmented networks, that accuracy dropped to just 44%. Other studies reveal significant variability in judgement—even among security experts—when it comes to CVSS scoring, given its inherently subjective characteristics.
Plus, because even context-enhanced CVSS scores are still tied to their baselines, they are unlikely to provide SecOps teams with the granular rankings necessary to appropriately prioritize millions of vulnerabilities.
Option #4: Utilize true risk management frameworks.
The urgent need to understand business risk as it relates to cybersecurity vulnerabilities has given risk to advanced frameworks such as NIST, ISO, FAIR, Risk IT, and JGERR. These frameworks typically define risk as a product of the likelihood that an incident will occur and the potential impact of such an incident on the organization (R = L x I).
While risk frameworks can be quite useful for optimizing the overall value-efficiency of enterprise cybersecurity strategies, they don't work very well at the highly granular level needed to rationally prioritize the remediation of vulnerabilities by SecOps teams with finite resources. That's because methods for determining likelihood (L) and impact (I) vary and have yet to be automated for application at scale.
Impact (I) is particularly problematic. Consider the process example below. SecOps teams dealing with hundreds of thousands of assets across their networks can't realistically execute this process hundreds of thousands of times. Also, such a process requires constant maintenance of an organization's cultural and historical knowledge over time—given how dynamic both enterprise environments and CVEs are. This complexity and labor-intensiveness explains why most risk management frameworks use a simple low/medium/high/critical scale for scoring impact.

The process of scoring vulnerabilities for their potential impact on an organization
Does not scale to meet the needs of SecOps teams dealing with millions of vulnerabilities.
There is also an option #5: denial. Some organizations apply denial by deciding without evidence that they are not large enough to have a real prioritization problem. Others apply denial by hoping that their chronic delays in vulnerability remediation will not give threat actors sufficient opportunity to act. But given the number of threat actors currently active worldwide and the complexity of even seemingly modest enterprise environments, this option is clearly the least viable of all.
The Solution: Contextual Prioritization
Given the high stakes at risk, vulnerability management at scale is a challenge that demands a solution. And that solution is Contextual Prioritization.
Contextual Prioritization provides SecOps teams with a practical way to score the risks represented by all the individual vulnerabilities present in their environments at scale and with sufficient granularity to actually be useful. It achieves this goal by:
- Automatically and continuously extracting signals from a combination of internal organization-specific activity, external open-source intelligence (OSINT), and private feeds
- Using statistical analysis to predict which assets on an organization's various subnets are likely to be targeted during the course of a threat actor's attack
- Leveraging machine learning models to derive actionable, organizationally contextualized prioritization from extracted signals, existing risk calculation techniques, statistical analysis of attack paths, and other relevant inputs
In addition to being scalable and granular, this statistical/ML-based model makes the most of incomplete knowledge, while continuously improving over time. It also takes advantage of the "Wisdom of the Crowd" so that bad decisions anywhere help mitigate risk everywhere.
We'll investigate the role of crowdsourcing in Contextual Prioritization in our next blog.
You Might Also Like
Secureworks has been acquired by Sophos. To view all new blogs, including those on threat intelligence from the Counter Threat Unit, visit: https://news.sophos.com/en-us/.