
As discussed in a Part 1 of this series, the problem of vulnerability management can be seen as an application of general risk management ideas to aging, complex, and error-prone IT infrastructure maintenance. Simply put, it's an answer to the following question: what weaknesses can my organization afford to leave unattended and what effort am I willing to put into remediation?
With a continuous stream of IT vulnerabilities to deal with every day, the task of exactly computing the risk on every one of them becomes literally intractable. Remediation teams need a better actionable solution to mitigate the actual risk, given limited resources.
When faced with the task of fixing millions of vulnerabilities, the most important questions one should ask are: What do I fix next? What are my top priorities for today?
In this blog, we first argue that giving teams an ordered ranking of remediation priorities is the best available solution to reduce organizational risk. Moreover, we insist this ranking should be done according to context specific to the organization and in a fault-tolerant way.
This blog presents the contextual prioritization process, using artificial intelligence techniques drawn from machine learning and collective intelligence. It’s a ranking method that is:
- Repeatable
- Efficient
- Granular
- Fault-tolerant
- Principled
We believe this ranking is a solid proxy value for the unrealistically hard task of perfect IT risk management.
Prioritization, Rank Aggregation, and Collective Intelligence
Prioritization
The problem of risk prioritization is a problem of total ordering on a set of objects. This is generally done using some kind of prioritization metric, a numerical value attributed to each object, or risk score. A score is just a (real) scalar number with an arbitrary scale. In itself, it does not have to mean anything or be directly interpretable. However, it can be used to compare objects to a set of fixed values (e.g., compliance thresholds), or to compare pairs of objects of similar nature.
Ranking vulnerabilities according to risk is, in itself, a risky endeavor. As we noted previously, this uncertainty arises from the fact risk is seldom well defined - subjective, fuzzy and high-dimensional. On the other hand, the potential cost of mistakenly ranking a vulnerability as low risk while it actually enables a real, substantial threat can be significant.
This high dimensional and subjective nature manifests itself in the following way: if you ask a number of different experts to rank vulnerabilities according to their available information and past knowledge, they might come up with a number of totally different rankings. This possible diversity of evaluation outcomes could be seen as a curse, but is in fact a statistical blessing (bear with us!).
Indeed, increasing the number and diversity of imperfect experts and aggregating their predictions has been shown, under certain conditions, to effectively produce unexpectedly accurate results.
Rank Aggregation
Reconciling expert's predictions about risk is akin to the task of finding an optimal aggregated rank. Put simply, minimizing disagreement between experts: this is formally known as the rank aggregation problem and is a very old problem.
One critical aspect to understand about Rank Aggregation is that not only is it provably impossible to always find an exact, perfect ranking that satisfies everyone, but even obtaining the optimum is considered extremely difficult.
As stated by Dwork & Al., given these facts, exact fairness is overkill: in the end, we only want the top-ranked vulnerabilities in the aggregated rank to be more significant and important than the bottom results.
Hence, what we aim for is a principled heuristic to aggregate diverse risk-rating expertise - including AI-based ones - into one ranking of remediation activities that minimize the global risk in an asymptotically, near-optimal way. Moreover, we want theoretical and empirical evidence using non-intrusive data collection, essentially obtaining real expert analyst signals.
Collective Intelligence
The field of collective intelligence gathers together different ideas from many disciplines, and is concerned with the aggregation of expertise and collaboration of many agents, in consensus decision making. We draw inspiration from this field, and more specifically from the phenomenon of Wisdom of the crowd as defined below, and derive the principles behind the prioritization ranking of vulnerabilities according to risk and context.
In short, our model aims at replicating the assessment of a wide range of context/risk-aware experts, each specialized in a narrow representation of risk and context given available knowledge. The aggregation of their assessment results in a final Contextualized Prioritization Score (CPS), enabling a principled, explainable and consistent order-rank on vulnerabilities.
What is the Contextual Prioritization Score (CPS)? It consists of two general steps:
- Independent expert assessments of vulnerabilities, according to context elements
- Aggregation of expertise into a global ranking
Step 1 - Independent Assessments
The first step is a set of individual assessments of simulated risk experts on each specific vulnerability using machine learning models and heuristics, each of them with respect to partial information. Note these simulated experts are devised by analyzing and reproducing real expert analyst signals, using machine learning and statistics.
For example, one artificial expert could be a machine learning model that predicts the relative importance of an asset to the organization, while another would look at the exploitation likelihood of a vulnerability given external threat intelligence data. Other simulated experts could also simply be based on the exposition of the asset to a public network or its uptime requirements.
This step assigns many different partial risk scores (called factors; in practice, real numbers) to vulnerabilities, each of them being mostly correct given a narrow view of the vulnerability’s context (called a risk element).
Step 2 - Score Aggregation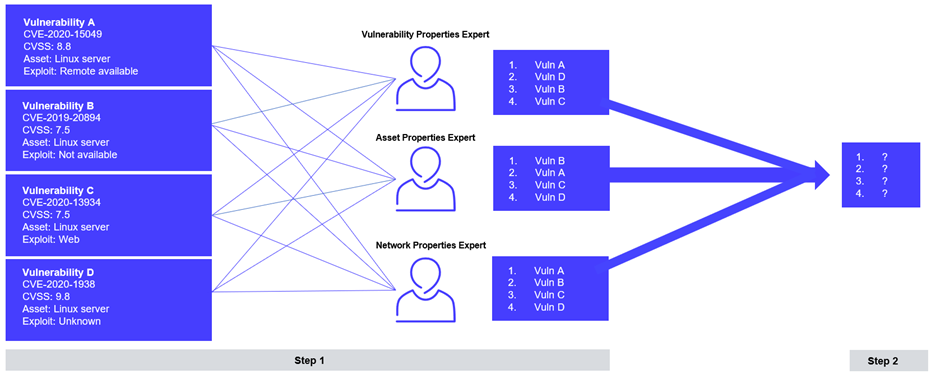
The second step is the weighing and aggregation of these many partial risk scores into an overall ranking that encompasses as many risk elements as possible.
By taking a large number of independent and diverse scoring assessments and aggregating them, albeit respecting a few requirements (defined below), we obtain a general ranking that is as close as possible to an optimal, context-aware ranking. That is to say, a ranking which minimizes the risk for every artificial expert.
The underlying principles of this method are drawn from the Wisdom of the Crowd statistical theory and the collective intelligence field of study. Inspired by Condorcet’s Jury Theorem, we transpose these ideas to an artificial intelligence setting by using simulated, artificial agents, instead of human ones. Let us first define what we mean by Wisdom of the Crowd.
Wisdom of the Crowd
In 1907, during a bovine weight guessing competition in an England county fair, the famous statistician and scientist Sir Francis Galton realized the aggregated predictions of many non-expert individuals could estimate the actual weight of the bovine with exceptional precision, much better than any single expert could do. Since then, the phenomenon has been replicated many times and is now dubbed “Wisdom of the Crowd.” It is a well-known and understood statistical phenomenon.
This principle is commonly used in the toolset of machine learning. The collection of simple, weak models into a surprisingly robust aggregation is called ensemble learning and is the basis for some of the most powerful models out there (Random Forest, Gradient Boosting Tree, Bootstrap Aggregation, etc.). The strength of the technique comes from the reduction in bias and variance when the individual guesses are aggregated. By adding decent voters, the probability of a majority of voters being wrong drops sharply.
A crowd is composed of agents, each performing an assessment, outputting a prediction upon a true value. The properties and assumptions of the models are as follows.
Desired Properties of the Model
- Individual biases of the agents cancel out if the diversity of agents is sufficient. Moreover, as the number of individual assessments grows, the uncertainty (variance) around the “true” values drops.
- Given a minimal set of desirable experts’ properties, adding more of them can only improve the ranking. Again, this operation scales efficiently and decreases variance.
Conditions for Agents in a Wise Crowd
- Competence: Assessments are principled, and agents have incentives not to predict incorrect values, i.e., agents give accurate results with a reasonable probability, more often than not (say with probability p > 0.5).
- Diversity: Agents have different background knowledge and have access to some local and reliable – but different – information on the assessment in question.
- Independence: Assessments are independent and without systematic biases, and no feedback loops are allowed; covariance is limited between factors.
- Limited Effect: The potential effect of an assessment is limited in the aggregation.
To score individual vulnerabilities, each agent is optimized to output a risk assessment given some restricted properties of the vulnerability. By carefully controlling and monitoring the predictions of these simulated experts, we expect the aggregation of their predictions to give a reasonable estimate of the global risk represented by the vulnerability, given the knowledge of its context.
Any of these simulated experts could be outlining a limited and fallible assessment of the true risk. It is only the aggregation of these assessments that converge to the actual risk.
The next section describes the application of this model to the assessment of vulnerabilities’ contexts into a hierarchy of assessment layers, as done by the Secureworks® Vulnerability Detection and Prioritization (VDP) engine.
The Onion Model
In this section, we examine the way we instantiated the crowd model. Each of our artificial experts is looking at different context elements of the vulnerability. VDP groups the individual assessments into a hierarchy of layers of context, like an onion, as illustrated below.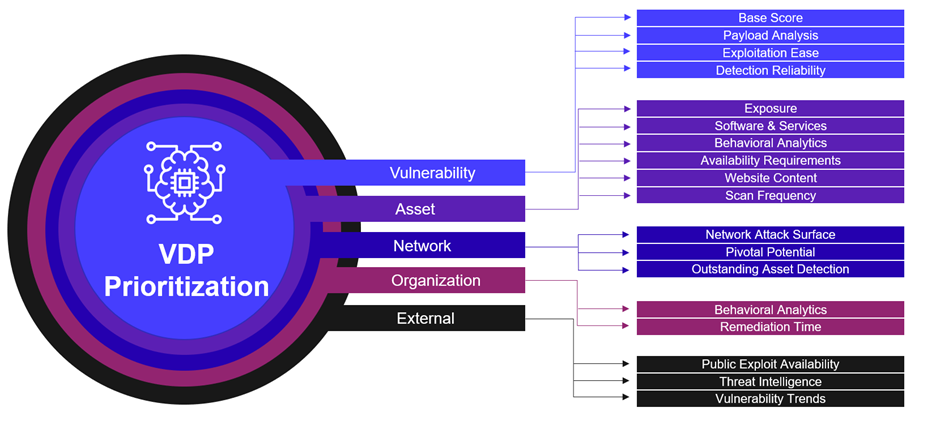
An industry-standard baseline CVSS score is used as a starting point, then successive layers of context are added by applying a multiplicative factor to the score, according to its local knowledge. The cumulative aggregation of these scores converges toward a comprehensive CPS (Contextual Prioritization Score), or contextualized risk score used for the final ranking.
Many of these factors are machine learning models, enforcing even deeper the concepts of collective intelligence and the idea of transferring real, acting expert analysts signals. We train the machine learning models to recognize, extract, and reproduce efficient behavior of attention, remediation, and prioritization.
In a future blog, we will take a look at these factors in much more detail. The final computation is presented in the last section of this post. Here is a graphical depiction of the process.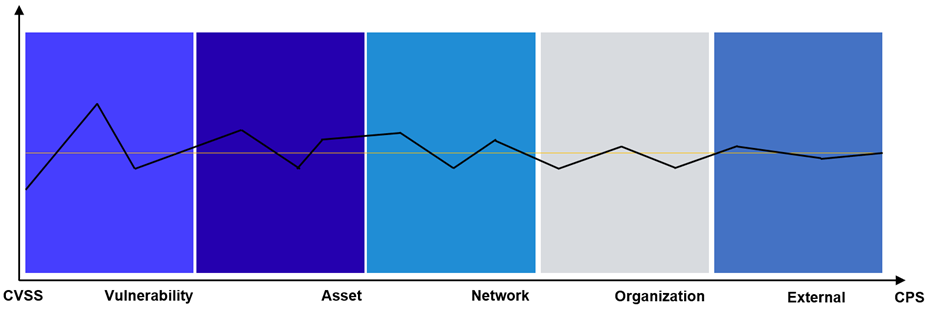
The score really makes sense when a large number of independent, diverse and reliable assessments are made on many vulnerabilities. The granularity induced and the inclusion of many context elements makes it possible to truly understand and trust priorities, then compare any pairs of vulnerabilities.
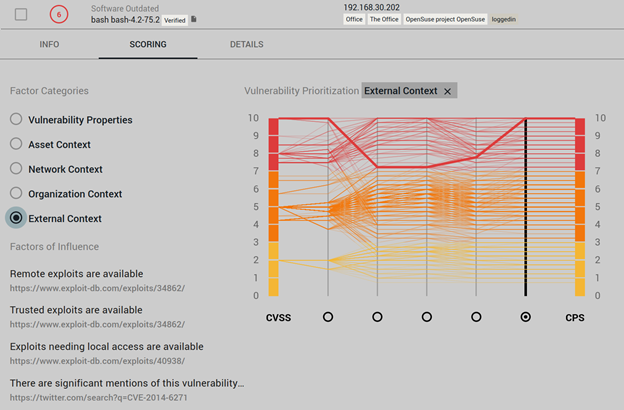
In this example, a vulnerability with high exploitation potential is being re-scored quite a lot. It seems like it’s laying on an unimportant asset, so the engine first drops the score by a factor of 30%, But given the availability of exploits and the evidence of trends from community discussions, the engine rescores the vulnerability to 10, making it a maximum priority vulnerability.
In practice, the CPS is not bucketed, as is presented in the infographic above and taken from the VDP user interface. The buckets are mere graphical conveniences. What we have in practice is shown in the graph below, where a real sample of vulnerabilities is showcasing the CVSS and CPS difference in distribution. Note the much improved granularity on the vertical dimension: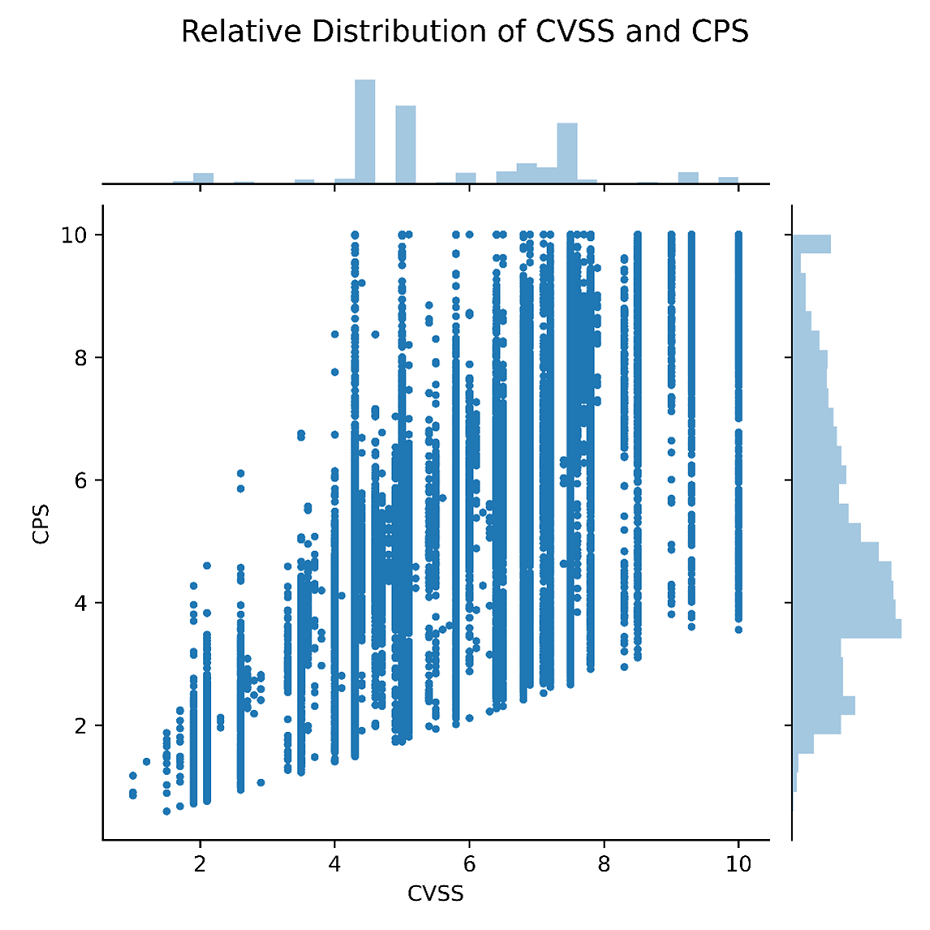
In the next section, we present the aggregation method to obtain the CPS score from the individual assessments.
CPS Aggregation Method
Here we dictate our prerequisites and assumptions, then describe the aggregation strategy that is the most straightforward and natural.
Requirements for the Aggregation of Scores
Given the assumptions described above (Wisdom of the Crowd), and with the due diligence of the development team coupled with the known effects of machine learning, we expect our aggregation method to satisfy the following requirements:
- Granularity: We wish the spread of scores to be wide enough so that the order is total; every vulnerability pair a, b can be compared with a > b or a < b (except for maxima/minima).
- Composability: If two independent assessments i and j both express an increase in priority, the combined score should be higher than both the scores limited to i or j alone.
- Fault Tolerance: By the nature of risk assessment and machine learning, errors are inevitable. We want to have a model that tolerates a limited amount of wrong assessments from fallible simulated experts.
- Consistency: The rank-inducing metric is kept on the same scale at each step, so we can easily remove, add, or tune factors without losing the scale invariance. This allows us to compare CPS to the CVSS score and plug it into compliance frameworks.
Much work has been written on the proper aggregation of ranking assessments. Most aggregation strategies use some flavor of averaging of assessments (linear, geometric, spectral), but all of them fail to satisfy our composability and consistency requirements.
Aggregation Formula
For each vulnerability, CPS components are computed sequentially and independently by individual simulated agents (but the order should not matter). Each agent outputs a multiplicative factor, usually small in magnitude (mostly between -10% to 10%), to feed the algorithm downstream.
For each vulnerability, CPS components are computed sequentially and independently by individual simulated agents (but the order should not matter). Each agent outputs a multiplicative factor, usually small in magnitude (mostly between -10% to 10%), to feed the algorithm downstream.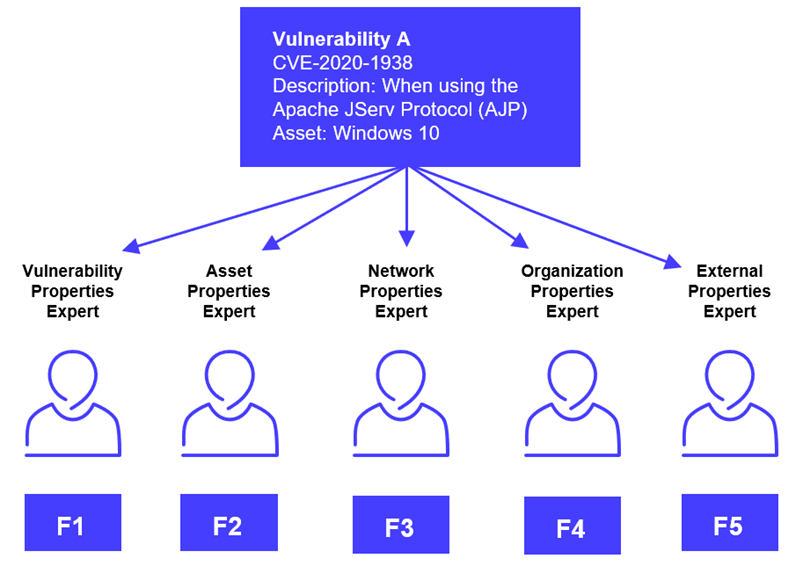
The final CPS score is computed by successively multiplying the factors with renormalization in order to keep the score interval fixed, no matter the number of factors. The formula to compute CPS is:
While the multiplication of factors enables composability, the renormalization is done at each assessment step and across all vulnerabilities. This nonlinearity allows consistency (fixed scale) at each step, and also allows all vulnerabilities to influence each other. In practice, it will drive the score of unimportant vulnerabilities down, and push the score of important vulnerabilities up.
One can see the initial step (the base CVSS score) as an uninformed prior, or a context-free, measure of risk. The uncertainty around this a priority risk score is quite high: the true risk could be much higher or much lower depending on the context.
The successive aggregation of each assessment, in practice, reduces the fuzziness around the true risk. The whole process converges toward a much narrower band of uncertainty.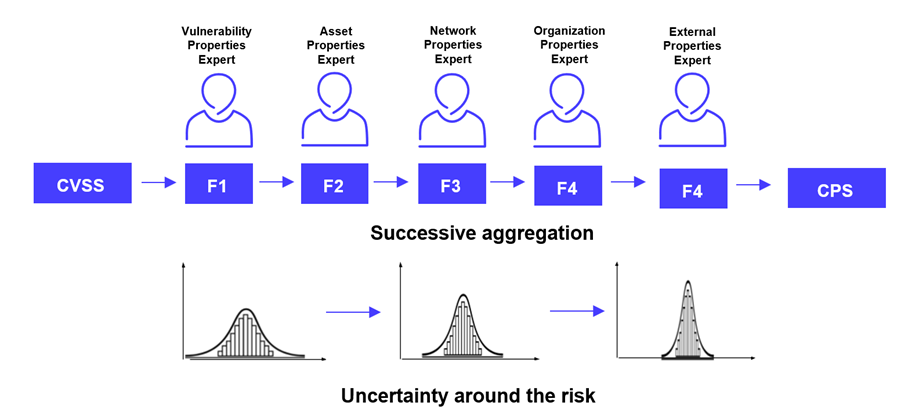
Note that continuous renormalization allows for easy addition, modification and subtraction of a factor with a limited impact on the global properties of the model, hence enforcing consistency and fault tolerance.
Call to Action
Want to learn more about our approach to contextual prioritization? Check out Secureworks VDP At a Glance.
Sources
Rank Aggregation
https://link.springer.com/article/10.1007/BF00303169https://dl.acm.org/doi/abs/10.1145/371920.372165
https://www.sciencedirect.com/science/article/pii/S0304397506003392
http://www.cse.msu.edu/~cse960/Papers/games/rank.pdf
Counteracting estimation bias and social influence to improve the wisdom of crowds
https://royalsocietypublishing.org/doi/10.1098/rsif.2018.0130The Wisdom of Multiple Guesses
https://web.stanford.edu/~jugander/papers/ec15-multipleguesses.pdfA solution to the single-question crowd wisdom problem
https://marketing.wharton.upenn.edu/wp-content/uploads/2017/08/11-02-2017-McCoy-John-PAPER.pdfCharacterizing and Aggregating Agent Estimates
http://aamas.csc.liv.ac.uk/Proceedings/aamas2013/docs/p1021.pdfGroups of diverse problem solvers can outperform groups of high-ability problem solvers
https://www.pnas.org/content/101/46/16385.fullCollective Intelligence
https://docs.google.com/file/d/0B4-bDrtyS3lXa0dzTXhuVWNpZWc/edit?pli=1Secureworks has been acquired by Sophos. To view all new blogs, including those on threat intelligence from the Counter Threat Unit, visit: https://news.sophos.com/en-us/.