
In the past 20 years, we’ve seen significant growth and investment in cybersecurity. However, there is still one area that security operations teams struggle to address: Vulnerability Management.
Vulnerability management is a well-established pillar of basic cybersecurity hygiene. Yet, cybersecurity incidents stemming from known vulnerabilities at large organizations with well-funded and equipped cybersecurity teams demonstrate the struggle to effectively remediate vulnerabilities on the most valuable targets for attackers.
In practice, vulnerability management requires most organizations to use one or multiple tools with the objective to regularly surveil IT assets and their respective vulnerabilities on a global scale. This activity is the starting point of a continuous process that ultimately aims at remediating these vulnerabilities.

Basic Vulnerability Management Process
With global corporate networks that can sometimes number in the hundreds of thousands of assets, compounded by the ever-increasing number of reported vulnerabilities, the output of these scanning products can quickly become overwhelming. The largest networks feature millions of vulnerabilities to consider for remediation.
Faced with the near-impossible task to remediate all of these vulnerabilities, organizations have to devise strategies to balance resource allocation versus remediation coverage. In other words: organizations must prioritize.
Prioritization is a crucial prerequisite activity for remediation. Organizations have to assess the risk each and every finding represents, and decide what should be addressed first. In order to do this, there are multiple methods that organizations use today.
Should I Prioritize Vulnerabilities using CVSS?
One very basic method to prioritize vulnerabilities is to use the severity ratings provided with the vulnerability definition (CVSSv2/CVSSv3) as a proxy value for risk calculation, and attempt to address all vulnerabilities surpassing a certain threshold. This approach is recommended (and sometimes mandated) at the very minimum by some industry standards like PCI-DSS (6.1/6.2), or the (now retired) NIST SP-800-117 and other governmental entities.
This approach might seem efficient at first, but using the CVSS score as an indicator of risk comes with critical limitations (especially for large environments).
Quick Recap on the CVSS
The CVSS score aims to measure the severity of IT vulnerabilities based on a vulnerability’s intrinsic properties. It is composed of a series of computations of fixed and ordinal values in the form of qualitative scores (low, medium, high) meant to be human-interpretable.
By design, it does not allow for a fine-grained analysis of the vulnerabilities. One of the main drawbacks of using the published CVSS scores as a proxy value for risk-based prioritization, in addition to their total absence of context, is its lack of granularity and diversity.
As others have noted, there’s only a few hundred “paths” available [1] when using the CVSS system. Whether you use V2 or V3 criteria, all final scores have to be chosen from 101 possibilities the scale allows (from 0.0 to 10.0).
A quick investigation on real data shows that of the 101 possibilities, the NIST only has attributed about 73 of them, and six scores make up to 67% of all vulnerabilities present in the National Vulnerability Database (NVD).
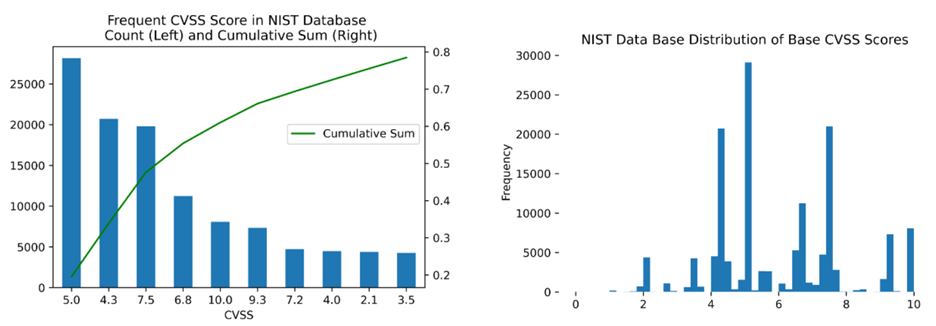
This is reflected in enterprise networks, where we usually see less than 60 different scores and about 12 scores making up to 90% of instantiated vulnerabilities.
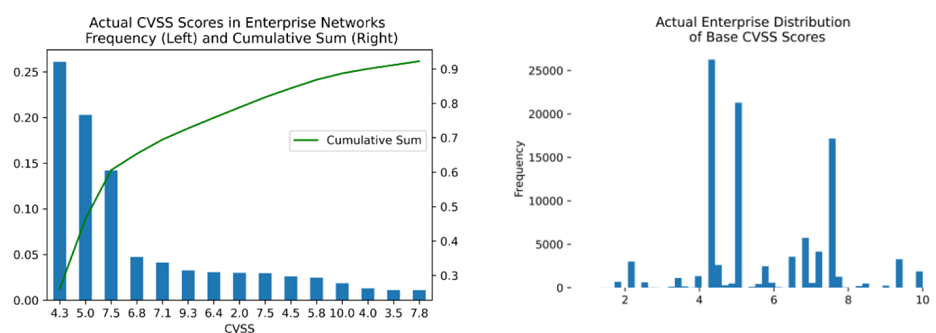
These trends confirm past publications stating that using the baseline-only published CVSS scores without any contextual information as a risk measure can be a substantial waste of time.
How about the Temporal and Environmental Components of the CVSS?
The baseline CVSS can be supplemented with more context-aware elements through its environmental and temporal scoring provision. This could very well be considered in order to gain sufficient granularity and contextual information density.
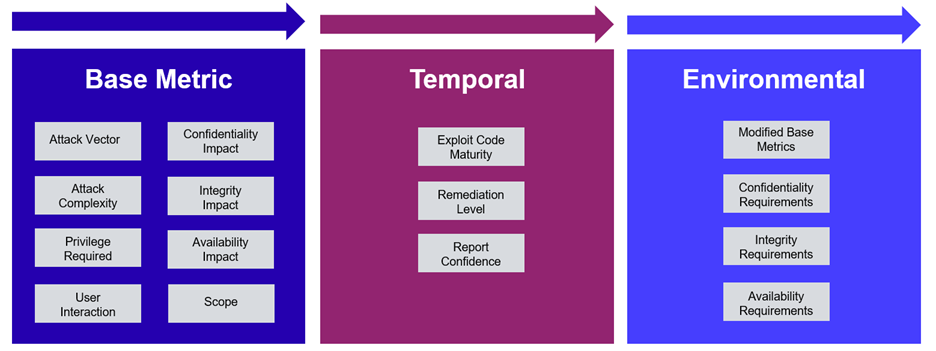
CVSS Evaluation Process
Unfortunately, this approach comes with already-established limitations, first as an error-prone activity that hardly scales with modern network complexity, and second, with great variability in judgement, even for the most seasoned security experts.
Does this approach give us more granularity? Even taking into account all the possible variations in the temporal and environmental factors – which would increase the potential number of “paths” to get the final score to a few thousands -- the system will still map this analysis to scores on the same scale, with 101 possibilities from 0.0 to 10.0. This remains insufficient to prioritize vulnerabilities in environments with even mere thousands of assets.
Can Risk Frameworks Help Prioritize Vulnerabilities?
More mature organizations will usually put the CVSS aside as a proxy value for risk, and might want to benefit from more elaborate risk management frameworks such as NIST, ISO, FAIR, Risk IT, or JGERR, that provide for more granularity and flexibility for risk evaluation.
Quick Recap on Risk Management Frameworks
Throughout frameworks of risk management, risk (R) is generally defined as a product of the likelihood (L) that an incident occurs (here the probability that a specific vulnerability be used by malicious adversaries) combined with the impact (I) of that incident on the organization. Or to put it another way: R (risk) = L (likelihood) x I (impact).
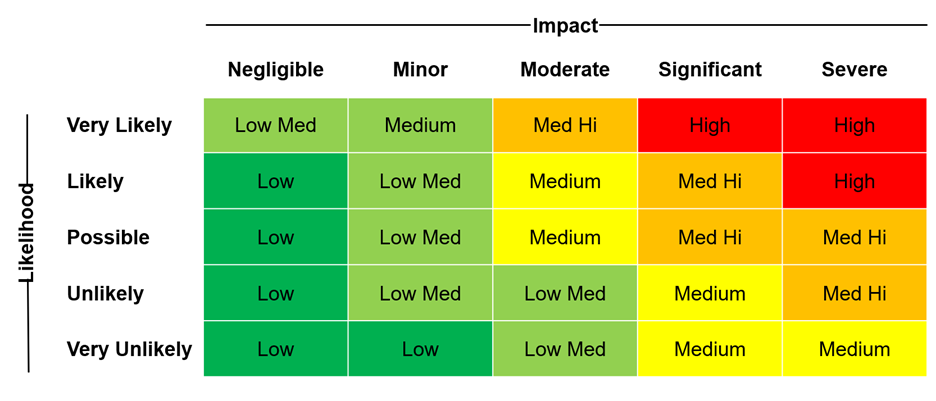
Pretty straightforward, right?
Over the years, quite a few papers have been published on refining the L part of risk with different approaches:
- By evaluating the potential for exploitation based on locally-installed network-based protection systems.
- By building machine-Learning models on historical vulnerability intelligence.
- By optimizing discovery-to-remediation models [2].
In fact, very little research has been published on automating the estimation of the impact (I) at scale, especially as it relates to specifics of the organization itself.
How Can We Approximate the Impact (I) Measure of Risk (R)?
Measuring the Impact portion of the risk a vulnerability represents is theoretically a task of “near-perfect knowledge” of the operational context in which it is exposed. Why? Because in practice, there are infinitely many factors to consider in evaluating the impact (I) to obtain a near-perfect measure.
As such, most risk frameworks aim for an approximate measure.
One of the most direct methods is to maintain specific business-related quantitative (precise dollar amount) or qualitative (low/med/high/critical) value scoring for each concerned asset, as assumed by the likes of FAIR, RISK IT or NIST SP800-30.

But it’s pretty obvious this approach comes with scalability issues. Networks with just thousands of assets can’t realistically execute all these steps for most of them.
To improve on that, other models suggest great speed improvements on impact evaluation, and rely more on the input of experienced practitioners as they try to distill and peer-review their organizational tribal knowledge.
While these approaches are theoretically sound, in practice they have to be limited in scope to a subset of the assets, for reasons of scalability and repeatability:
- Strenuous work is required to maintain the organization’s cultural and historical knowledge over time, which could quickly become a labor-intensive task, incompatible with the high dynamism and continuous stream of vulnerabilities of modern IT environments [3].
- The human-driven estimation at the core of these systems is barely repeatable over time: potentially influenced by fatigue, depression, resentment, or simply because of undue influence from internal corporate politics.
A more modern approach should include a continuous automated and repeatable evaluation of all vulnerabilities within their organizational context.
This approach should not discard work that has already been done. Rather, it should build on the manual labor required by existing frameworks and risk evaluation methods, and provide a single risk-based, granular metric for vulnerability prioritization.
Introducing Contextual Prioritization
Through this series of blog posts, we’re going to discuss a risk-based data aggregation model called Contextual Prioritization that brings together both elements of the likelihood (L) of a vulnerability being successfully exploited, as well as its estimated Impact (I) for the organization.
This scalable and flexible model works in multiple ways:
- By continuously extracting and learning from a large number of expert analysts signals in a non-intrusive way from internal, organization-specific activity, external, open-source intelligence (OSINT) and private feeds. This passive signal extraction makes it capable of supplementing existing risk calculation techniques and understanding organizational priorities by transferring them to machine learning models.
- By being supplemented with elements of unsupervised machine learning, in order to statistically characterize the different assets on subnets as a way to simulate attacker’s intuition and behavior when targeting specific systems in a defined network.
- By being flexible enough so it can be complemented with more simple heuristics in order to account for pre-existing risk categorization techniques.
This statistical and machine-learning driven approach of the model makes it:
- Much more scalable than traditional methods, as this technique can be applied continuously to the entire network and not just a subset of assets.
- Able to work with incomplete knowledge (partial information) and naturally improves as the data set does.
- Able to evaluate risk in a fault-tolerant way through the principle of Wisdom of the Crowd, with more non-competing elements to evaluate the risk of making wrong judgements decreases.
On the Importance of the Wisdom of the Crowd
This model relies on the principle of the Wisdom of the Crowd for risk computation through statistical analysis and machine-learning techniques. We’ll explore in our next post.
Call to Action
Want to learn more about contextual prioritization? Check out this white paper.
Read Part 2 in this series - Vulnerability Prioritization, Part 2: Redefining Vulnerability Remediation Prioritization.
Sources
[1] Scarfone, K., & Mell, P. (2009). An analysis of CVSS version 2 vulnerability scoring. 2009 3rd International Symposium on Empirical Software Engineering and Measurement.
[2] VULCON: A System for Vulnerability Prioritization, Mitigation, and Management
KATHERYN A. FARRIS, ANKIT SHAH, GEORGE CYBENKO, RAJESH GANESAN and SUSHIL JAJODIA, https://doi.org/10.1145/3196884
[3] The Effects of Information Overload on Software Project Risk Assessment*
Robin Pennington Brad Tuttle https://doi.org/10.1111/j.1540-5915.2007.00167.x
Secureworks has been acquired by Sophos. To view all new blogs, including those on threat intelligence from the Counter Threat Unit, visit: https://news.sophos.com/en-us/.