
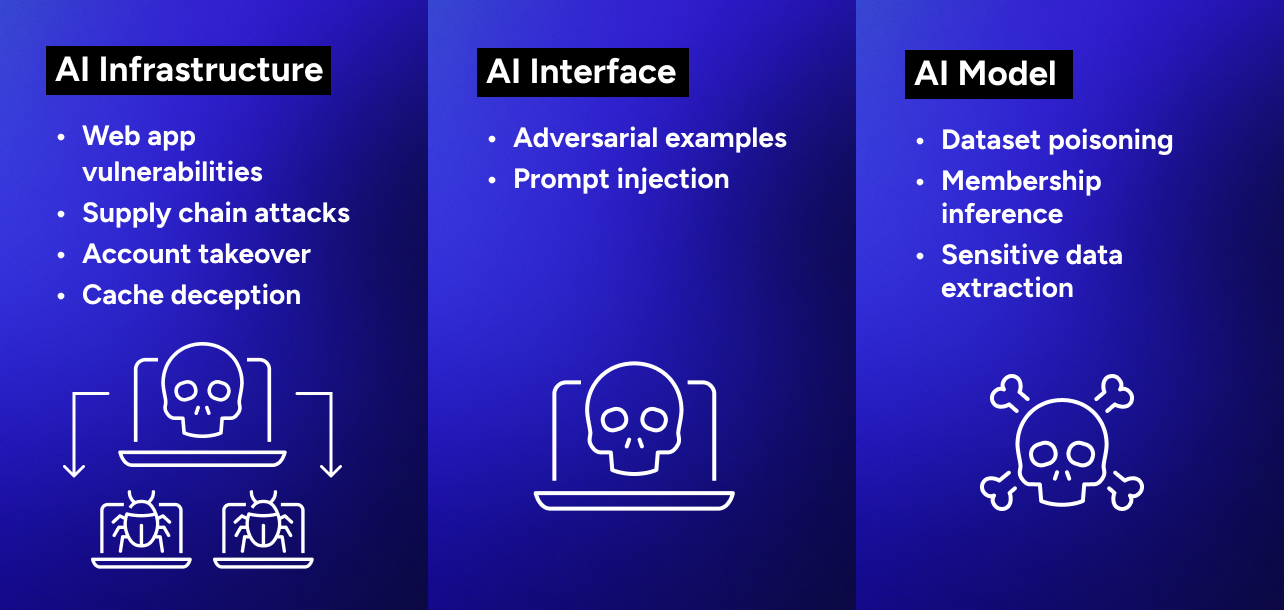
Figure 1. Vulnerability classes in AI systems.
Artificial intelligence (AI) systems are a rapidly evolving part of the technology landscape. For many industries, they are becoming a critical component. When it comes to securing these systems, many security practitioners and network defenders consider them a cause for concern.
This article discusses the attack surface of AI systems using the STRIDE framework (see Table 1). STRIDE is a threat modeling framework that supports a proactive approach to improving security by identifying, understanding, and addressing threats before systems are implemented. STRIDE stands for Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege. The framework helps us better understand possible attack paths in an AI system. Using a classic framework such as STRIDE to understand novel threats helps organizations strengthen their AI applications.
| AI infrastructure | AI interface | AI model | |
| Spoofing | Model supply chain | Prompt injection | Model Trojan |
| Tampering |
Prompt injection Adversarial examples |
Dataset poisoning Hyperparameter tampering |
|
| Repudiation | Deep fakes | ||
| Information disclosure | Cache deception |
Adversarial examples Server-side output can be fed directly back into LLM and vice versa |
Membership inference Sensitive data extraction Model extraction Improper model output filtering |
| Denial of service | Improper model output filtering | ||
| Elevation of privilege |
Model supply chain Cache deception |
Table 1. The STRIDE framework.
Examining new attack classes that are specific to AI technologies helps develop new perspectives on classic attack scenarios. As the field of AI security progresses, new models, applications, attack types, and modes of operation are being developed daily.
Attacks against AI infrastructure
Developers are increasingly embedding AI models deeply into complex systems. Tampering with the inputs and outputs of models or with the surrounding infrastructure can lead to harmful and unpredictable outcomes such as unexpected behavior, interactions with AI agents, and impacts to chained components.
Spoofing occurs if an attacker impersonates a trusted source during the model or component delivery process. This technique could let the attacker introduce malicious elements into the AI system. Spoofing could also be used as part of a model supply chain attack. For example, if a threat actor infiltrates a third-party model provider like Huggingface where code execution on AI output occurs downstream, they could in some use cases gain control of surrounding infrastructure by infecting upstream models.
Sensitive data exposure is a common issue with any web application, including those that serve AI systems. In a March 2023 example, a Redis misconfiguration caused a web server to expose private data. This cache deception attack against ChatGPT created an elevation of privilege and let an attacker retrieve data with a subsequent request. Web applications in general are susceptible to the classic OWASP top 10 vulnerabilities such as injection attacks, cross-site scripting, and insecure direct object references. This situation may apply to web applications that serve AI systems, as they are highly visible targets that can bring fame to any threat actor who successfully exploits them.
Denial of service (DoS) attacks could also pose a threat. By overwhelming the model supplier’s infrastructure with traffic, an attacker can render an AI service unusable. Designing resilience into the infrastructure and applications surrounding AI models is a first step towards a safe implementation of AI systems, but it is not enough.
Attacks against model training and inference
The attacks discussed in this section are against trained models and against the newer class of third-party generative AI systems.
AI models are susceptible to specific threats during the training and inference stages. Dataset poisoning and hyperparameter tampering are attacks under STRIDE’s tampering category where the threat actor injects malicious data into the training dataset. For example, an attacker could intentionally feed misleading images into a facial recognition AI, causing it to misidentify individuals.
Another common attack is through adversarial examples, a type of information disclosure or tampering threat. Attackers manipulate inputs to the model to cause it to make incorrect predictions or classifications. These actions could reveal sensitive information about the model's training data or trick it to act in unintended ways. For example, a team of researchers showed that adding small pieces of tape to stop signs could confuse image recognition models embedded in self-driving cars, which could lead to dire consequences.
Model extraction is a pernicious form of attack that falls under STRIDE’s information disclosure category. The attacker’s objective is to replicate a proprietary trained machine learning model based on its queries and responses. They craft a series of carefully designed queries to the model and use the responses to construct a copy of the target AI system. This attack could infringe on intellectual property rights and can lead to significant economic losses. It can lead to additional threats because attackers who possess a copy of the model can execute adversarial attacks or reverse engineer the training data. Maliciously using the model output can cause harm at a very large scale. Leveraging generative AI to create deep fakes or large-scale production of realistic-looking fake content can occur when programmers blindly use the output of coding assistants and push insecure code to production.
Novel attacks against large language models
The prevalence of large language models (LLMs) has been the impetus for new attack types. LLM development and integration is an extremely hot topic and as a result, new attack patterns are published every week. Therefore, the OWASP project has started the draft process for the first version of OWASP Top 10 for Large Language Model Applications.
Prompt injection includes jailbreaking, prompt leaking, and token smuggling. In these attacks, the adversary manipulates the input prompt to trigger unwanted behavior from the LLM. This manipulation can lead to the AI generating inappropriate responses or leaking sensitive information, which aligns with STRIDE’s spoofing and information disclosure categories. These attacks can be especially potent when AI systems are used in conjunction with other systems or in a software application chain. APIs could be leveraged in ways that are not publicly exposed, such as improper model output filtering, or server-side output being fed to the model. For example, frameworks like Langchain let application developers quickly deploy complex applications on top of public generative models and other public or private systems like databases or Slack integrations. Attackers could craft a prompt that tricks the model into making API queries that it would otherwise not be allowed to do. Equally, an attacker could inject SQL statements into a generic non-sanitized web form to execute malicious code.
There is also an increased risk of membership inference and data extraction, which are information disclosure attacks. An attacker could leverage a membership inference attack to infer in a binary fashion whether a particular data point was in the training set, raising privacy concerns. A data extraction attack lets an attacker completely reconstruct sensitive information about the training data from the model's responses. A common scenario occurs when LLMs are trained on private datasets. The model could possess sensitive organizational data and potentially let an attacker create specific prompts to extract confidential information.
Combining one or more of these attack approaches lets threat actors engineer sophisticated attacks with serious implications. Large language models have proven susceptible to training dataset poisoning at the fine-tuning phase, even with minimal manipulation. Moreover, tampering with familiar public training data has been shown to be viable in practice.
These weaknesses open the door to publicly available language models serving as Trojan models. Outwardly, they function as anticipated for most prompts, but they hide specific keywords introduced during fine-tuning. Once an attacker triggers these keywords, the Trojan models can execute a wide range of malicious behaviors. These potentially include piecing together complex tasks within critical applications, achieving elevation of privilege, rendering systems unusable (DoS), or disclosing private sensitive information. As the technology evolves, these threats remind us of the need for unceasing vigilance.
Attacking software 2.0
AI researcher Andrej Karpathy noted in a 2017 seminal article that the arrival of the new generation of Deep Neural Networks models marked a paradigm shift in the way that we must conceptualize software. Instead of being defined by a set of instructions, AI models are defined almost entirely by the data used to train them. They are expressed not in the language of loops and conditionals but in terms of continuous vector spaces and numerical weights. At its core, a trained neural network blurs the boundaries between a database and a set of instructions. It echoes the historical transgression of conflating code and data that created memory overflows, as first manifestoed in "Smashing the Stack for Fun and Profit," published in Phrack Magazine in 1996.
The inherent structure of machine learning has created new avenues for exploitation and has spawned new classes of threats. Attacks such as dataset poisoning, model extraction, membership inference, and adversarial examples are innovative and worrisome abuses of machine learning's fundamental operations. They are serious issues that must be considered by the AI and security community. It may be time to consider a new manifesto: "Smashing the Model for Fun and Profit."
Conclusion
The field of AI threat modeling is expanding at a pace that mirrors the rapid advancements being made in AI and cybersecurity. As our reliance on AI grows, so too does the importance of securing these systems. Many of the attacks discussed in this article may not be novel but, given the world's swift embrace of AI technology, raising awareness of them and implementing defensive measures should be of the highest priority. Adopting a structured approach like the STRIDE framework can help businesses identify potential threats and develop robust defenses.
Organizations must act now to understand the attack surface of their AI systems, which includes developing a comprehensive plan to include security in the development lifecycle.
Secureworks has been acquired by Sophos. To view all new blogs, including those on threat intelligence from the Counter Threat Unit, visit: https://news.sophos.com/en-us/.