
Introduction
In cybersecurity, news regarding new vulnerabilities appears continuously every day through an array of various sources, be it news networks, social networks, blogs, security advisories, etc. These fall under the umbrella of open-source intelligence (OSINT). Yet not all vulnerabilities generate the same level of interest and length of discussion.
As such, one interesting aspect of vulnerability prioritization is to consider what types of vulnerabilities are currently trending in these OSINT sources, in order to establish the types of vulnerabilities an attacker might favor. For example, if discussions in public sources and underground networks currently mention reflected XSS attacks on particular frameworks more often than usual, other attackers reading these discussions could be tempted to attack other similar XSS vulnerabilities or find similar inflection points in other frameworks. Attackers, just like cybersecurity experts, are very much influenced by trends in exploitation methods.
The goal of the approach presented here is to identify the patterns or trends underlying online discussions. These are what we aim to model in order to generalize which vulnerabilities might receive more attention from attackers, regardless of the vulnerability’s direct mentions (e.g., its CVE number) in online discussions. The goal is the identification of the underlying concepts associated with online cybersecurity discussions, first to assess the importance of existing vulnerabilities, and second to use this representation as input to future predictive models. To extract this information, a natural language approach is employed, which uses machine learning and, more specifically, topic modeling.
In short, it is possible to build a representation of a vulnerability that captures both its intrinsic features as well as its relationship with the external world.
This framework aims to:
- Create a representation that encodes the semantic meaning of vulnerabilities, i.e., topics from the textual descriptions of all disclosed vulnerabilities to date.
- Crawl online InfoSec discussions and apply them to a topic model, so as to obtain a weighted list of topics, which we call trends.
- Combine the previously built trends to their respective topics in a vulnerability, in order to indicate importance to current InfoSec discussions.
Methodology
In order to accomplish these goals, we can use topic modeling, which is an unsupervised machine learning technique in which a number of topics are automatically extracted from a text corpus, along with each topic’s probability of appearing in any of the texts. A topic consists of one or more weighted words. A higher weight indicates a higher importance to the topic. A topic represents an underlying concept extracted from the text through statistical analysis.
For example, there are a great number of disclosed command injection vulnerabilities out there, each with a different but similar description. This technique can capture a generic topic representing the words associated with command injection vulnerabilities, looking somewhat like this:

Figure 1: An example of a command injection topic
A prominent topic modeling technique is Latent Dirichlet Allocation (LDA), which is a generative model that computes the probability of a word being associated with a topic[1] LDA has been proven to be effective in previous research and applications[2,3], and is one of the most common topic modeling methods.
Creating the Topic Model
First, let’s extract the textual definition of all vulnerabilities in the National Vulnerability Database (NVD) of the NIST, each associated with a CVE number. These texts are then processed, as depicted by Figure 2. In step 1, URLs and common words are removed, the text is split into tokens (single words), and the words are lemmatized to group together different inflections of a word.

Figure 2: Filtering of a description’s words, and splitting into tokens
These lists of tokens can then be transformed into a numerical representation using the bag-of-words model, as depicted in Figure 3. In this new representation, each token is identified by an ID and its number of occurrences, in which the ID is chosen based on its first appearance in the definitions. This transformation is necessary since LDA requires numerical inputs.

Figure 3: Transformation of a description’s tokens into a numerical representation
These are used as input to LDA, as shown in Figure 4, which generates a set of topics identified by a series of words and an importance factor between 0 and 1. This model is implemented using online learning. New published vulnerabilities are fed to the model daily and the model is updated incrementally.
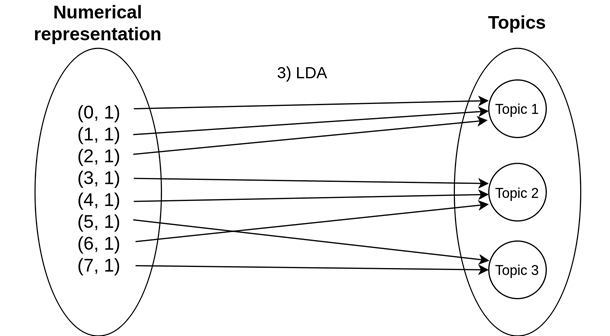
Figure 4: Association of words in numerical form to their topics through LDA
Building Trends from Online Discussions
Once we have learned a suitable model for vulnerabilities, one that understands the specifics of language in the description of vulnerabilities, we gather online discussions of vulnerabilities and exploitations from various public sources. While a number of previous works have extracted information from online discussions in order to build models[4,5,6,7], none applied them to a topic model in the same way this blog details. Now, let’s process text posts from discussions in the same way as specified in Figure 2 and Figure 3, and apply them to the existing topic model.
This results in a vector of weights for each text post, where each topic’s importance to this discussion is expressed by a number between 0 and 1, named a weight. By averaging these vectors together across all posts, we obtain a final single vector denoting the relative importance of each of our topics in what we observe in online discussions. We call those “trends”. In the end, by extracting the topics with the highest weights, we obtain the set of current trends. Figure 5 describes the creation of trends :
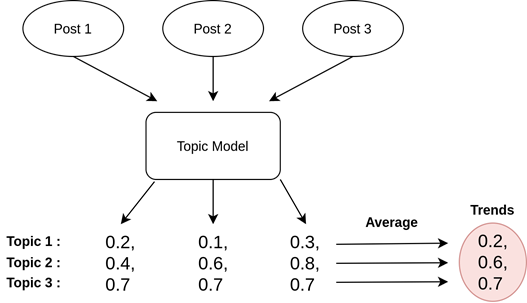
Figure 5: The creation of a trends score from online discussions
Scoring Vulnerabilities
Finally, we look back at the vulnerabilities from the NIST database which were used to build the initial topic model, and identify the ones with topics matching the newly established trends. This is done by applying the dot product to each vulnerability topic vector and the trends vector, or in slightly more human language, by computing the product of each of a vulnerability’s topic weights and its corresponding trend weights, and summing them. This provides a final Vulnerability Trends Score (VTS).
The higher the VTS is, the more closely this vulnerability matches with online discussions.

Figure 6: The dot product between the vulnerability topics and the trends
The framework can be summarized in the figure below. First, the topic model is trained with vulnerability descriptions, and outputs a number of topics:
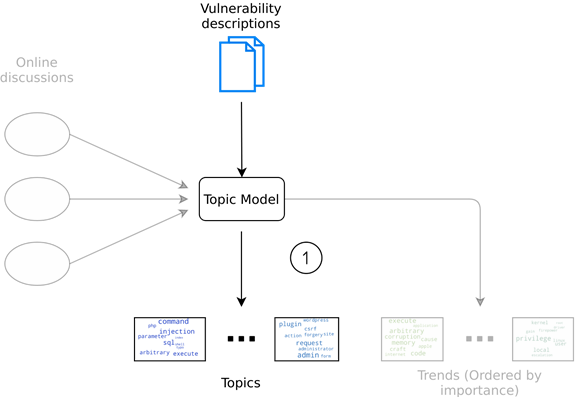
Second, online discussions are run through the same topic model to establish which of the previously obtained topics are most important for these discussions:
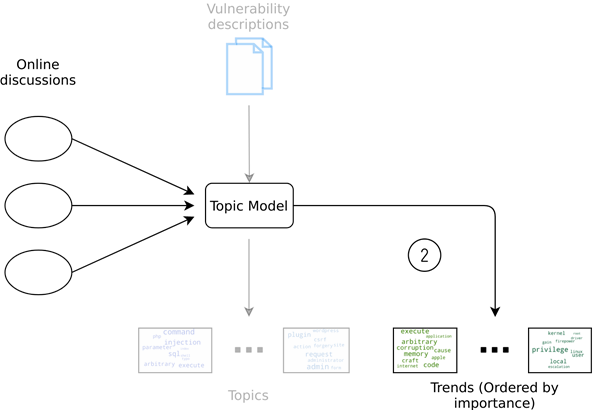
Figure 7: Overview of the approach
Results
Examples of a Use Case
Let’s see how this works in practice, by exploring data from June 2020. Using the previously shown method, 30 topics (why 30? See the Appendix below) were identified on all of NIST’s vulnerabilities, each identifying a concept observed in vulnerability descriptions. Then, data was gathered from online discussions, such as these tweets from Twitter:
- "We have created the first write-up on the recent Apache Tomcat RCE (CVE-2020-9484), read here: [url] #infosec #javahacking #exploit #tomcat #deserialization #webapplicationhacking #vulnerability"
-https://twitter.com/redtimmysec/status/1266695889470586880 - "#CVE-2020-1938 Apache Tomcat from file reading to RCE involving AJP protocol"
-https://twitter.com/pyn3rd/status/1230565467661619204 - "Apache Tomcat AJP Vulnerability (CNVD-2020-10487/CVE-2020-1938).This vulnerability was discovered by a security researcher of Chaitin Tech . You can read any webapps files or include a file to RCE .JUST A POC-GIF with no DETAILS Tomcat has fix this vulnerability ,UPDATE! [url]"
-https://twitter.com/chybeta/status/1230489154468732928
When applying the topic model to these tweets, a weight for every topic of the model is obtained, relative to these specific tweets. This is what we identify as trends. Among others, these three topics, in a human-interpretable form, came out as important:
- Topic A, related to file upload vulnerabilities
- Topic B, related to applications having default settings and making HTTP requests
- Topic C, related to code execution vulnerabilities
The topics can be visualized using word clouds:
Trend A

Trend B

Trend C

Finally, we can use the trends and the vulnerabilities’ topics to obtain a VTS for each vulnerability, using the method described previously.
The top-ranked vulnerability comes out as CVE-2020-19382 , which identifies an Apache Tomcat vulnerability, code-named Ghostcat, enabling attackers to upload files through a default connection, and potentially obtain a remote code execution. This vulnerability appearing as the most important for that time period is expected, given that many tweets mention Tomcat vulnerabilities, and some directly speak of this vulnerability. More interestingly, other vulnerabilities matching with topics A, B and C will also have a high trending score, while not necessarily being the most mentioned online.
Trends Over Time
The topic model is run in an online mode (i.e., updated with new vulnerabilities as they appear), which lets it retain its topic distribution. We observed some gradual evolution over time for our computed trends, following important events happening in the infosec world. Specifically, we tracked the scores of 3 notable trending topics over the year of 2021.
Our first trend identifies cross-site scripting (XSS) vulnerabilities, as can be observed from its word cloud :

Figure 9: XSS trending topic
Following this trend over the past months, we see a peak in score in March 2021. This coincides with the publication of a WordPress ivory plugin XSS, which affected 60,000 domains. This event generated online discussions, which in turn were reflected in our trends.

Figure 10: XSS trend over time
A second noteworthy trend is linked to use-after-free vulnerabilities:

Figure 11: Use-after-free trending topic
When exploring the evolution of this trend, we can observe a peak of interest around the end of March 2021. This is related to a controversy where researchers introduced use-after-free vulnerabilities in the Linux kernel as part of a research project. An important aspect of our approach can be seen here: although the vulnerabilities in question were not critical, they generated a lot of interest over use-after-free vulnerabilities. This in turn influences attackers in their choice of attacks, hence the importance of identifying the underlying concepts of vulnerabilities.

Figure 12: Use-after-free trend over time
Finally, our third trend is related to macOS code execution vulnerabilities:

Figure 13: MacOS code execution vulnerabilities trending topic
Following this trend’s evolution through time, we can see the impact of the publication of multiple critical vulnerabilities in macOS Big Sur in August and September of 2021, and how this specific trend increases in score:

Figure 14: MacOS code execution vulnerabilities trend over time
Conclusion
What was obtained from the method presented in this blog is a semantic mapping of vulnerabilities, and a single metric linking vulnerabilities to current trending topics. These are used as numerical representations, linking online discussions and the semantic of a description to a specific vulnerability. These new features bridge the gap between the underlying concepts behind a vulnerability and actual numerical features which can be used by a machine learning model.
Appendix
Parameter Tuning
LDA requires a fixed number of topics as a parameter. In order to validate this parameter choice, multiple values were tested and evaluated through the coherence[8] of topics: a highly coherent topic will have top scoring words that are similar between themselves and different from top words of other topics. Overall, this metric serves as a way to benchmark models in order to compare their effectiveness. The test included n numbers of topics from 5 to 100, and the best results were found with n=30: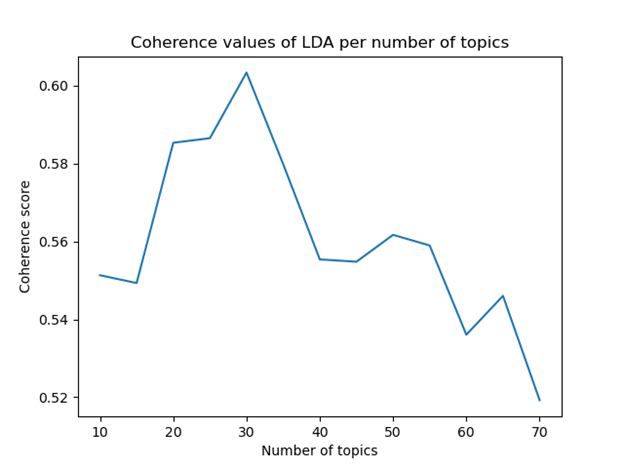
Figure 15: Coherence test for identifying the number of topics providing the best clustering
Validation
Through this approach, the highest trending vulnerabilities are indirectly linked to online discussions through the use of topics. In order to validate that the vulnerabilities with the highest trending scores are in fact directly related to online discussions, an hypothesis test was conducted to assert that the descriptions of trending vulnerabilities are more similar to online discussions than a random sample of descriptions are to the same online discussions. To compare the similarity of the texts, we used the term frequency-inverse document frequency (TF-IDF) [9], which is a commonly used similarity measure to identify how relevant each word is to a text.
We sampled the 1000 vulnerabilities with the highest VTS, extracted their descriptions, and compared each one with the online discussions using TF-IDF. We then sampled 1000 random descriptions from all vulnerabilities in the NIST database, and compared them as well to the online discussions. With this, we obtained a distribution of similarity measures for the trending vulnerabilities, and another distribution of similarity measures for the random vulnerabilities. We then conducted a permutation test on these two distributions, and confirmed that the similarity scores of the trending vulnerabilities are significantly higher than the similarity scores of the random sample; we reject the null hypothesis with a p-value approaching 0.000.
References
[1] Blei, David M., Andrew Y. Ng, and Michael I. Jordan. "Latent dirichlet allocation." Journal of machine Learning research 3.Jan (2003): 993-1022.
[2] Lee, Suchul, et al. "LARGen: automatic signature generation for Malwares using latent Dirichlet allocation." IEEE Transactions on Dependable and Secure Computing 15.5 (2016): 771-783.
[3] Liu, Linqing, et al. "Detecting" Smart" Spammers On Social Network: A Topic Model Approach." arXiv preprint arXiv:1604.08504 (2016).
[4] Mittal, Sudip, et al. "Cybertwitter: Using twitter to generate alerts for cybersecurity threats and vulnerabilities." 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). IEEE, 2016.
[5] Chen, Haipeng, et al. "Using twitter to predict when vulnerabilities will be exploited." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2019.
[6] Hoffman, Matthew, Francis R. Bach, and David M. Blei. "Online learning for latent dirichlet allocation." advances in neural information processing systems. 2010.
[7] Shrestha, Prasha, et al. "Multiple social platforms reveal actionable signals for software vulnerability awareness: A study of GitHub, Twitter and Reddit." PLoS One 15.3 (2020): e0230250.
[8] Röder, Michael, Andreas Both, and Alexander Hinneburg. "Exploring the space of topic coherence measures." Proceedings of the eighth ACM international conference on Web search and data mining. 2015.
[9] Ramos, Juan. "Using tf-idf to determine word relevance in document queries." Proceedings of the first instructional conference on machine learning. Vol. 242. 2003.
Secureworks has been acquired by Sophos. To view all new blogs, including those on threat intelligence from the Counter Threat Unit, visit: https://news.sophos.com/en-us/.