
The MITRE Corporation’s 2019 MITRE ATT&CK® Evaluation results have been public for more than a month now, and with that release our industry gained unprecedented insight into 21 endpoint security products. The credit goes to MITRE for creating an attack-driven evaluation modeled after known threat actor behaviors, and for driving increased adoption of the approach. The field of vendor participants doubled in size since last year’s inaugural evaluation.
The published results have triggered a flood of press releases and blog posts from product vendors claiming victory from the results and basing those claims on carefully crafted or self-biased data analysis. Unfortunately, all the jockeying and positioning among vendors isn’t helping security teams get what they really need: information on how to leverage the results to advance their security objectives.
We sympathize with the rising level of confusion that security minded readers must experience as they try to navigate and compare all these claims in the marketplace. So instead of contributing to the confusion even more, we would like to give you a transparent view of our own experience in the evaluation and offer three guidelines to help you interpret the results in a more pragmatic way. The guidance is from our perspective as one of the product evaluation participants, a company protecting thousands of customers every day, and as security industry optimists who believe that collectively we can secure human progress from malicious adversaries.
The insights we’ve chosen to share may lean on specific results from the evaluation, so we’ve anonymized the other evaluation participants and assigned them constellation-inspired codenames instead. Our intent is not to obscure any vendor’s results, but rather keep the focus on providing pragmatic analysis. The raw results are available publicly from MITRE, and our hope is that security teams who are motivated to make improvements will find our ideas helpful to better orient their own take-aways and decisions.
Guideline #1: Visibility coverage shows industry-wide advantages against adversaries, but it also highlights the challenge of trying to determine product differences.
Most of the world is still in the thralls of COVID-19 social distancing and economic uncertainty. In this context, a message of hope - in any size, shape, or context - is most welcome. We find a hopeful message in the overall visibility performance seen across endpoint security vendors showcased in the MITRE evaluation results. Figure 1 shows a basic count of telemetry coverage across the 134 attack sub-steps. Across vendors, we see broad visibility capabilities of the simulated APT 29 attacks. We believe this breath of visibility also translates well to other threat actor activity. In the context of the security industry, which often finds it easier to focus on criticism or pessimism driven from the overwhelming feeling that adversaries have the upper hand, our collective visibility performance is an encouraging outcome. The industry is making progress against adversaries and evidence of that progress starts with increasing visibility coverage. We can’t stop attacks that we do not see.

Figure 1: Telemetry indicating visibility across 134 attack sub-steps. Metrics as shown are without allowing for configuration changes during the evaluation.
While there is still room for all of us to improve endpoint visibility, it’s also difficult for security teams to differentiate products because of the similarities in performance today. Half of the top participants are closely grouped covering 75% or more of the specific attack sub-steps, with the top vendors within roughly 5% of each other. There are a handful of different ways to slice this visibility data, but you will find that the overall message remains the same. Great news across the security industry, but it’s relatively difficult for consumers to determine visibility differences in the market.
One major reason it’s so challenging to differentiate is that the evaluation was for endpoint only. For example, our own product offerings Red Cloak™ Threat Detection and Response (TDR) and Managed Detection and Response (MDR) are not solely endpoint solutions. Our security strategy focuses on advancing broad visibility to combat threats, including network sensors, syslog sources, cloud service API integrations, and even partnerships with other endpoint agents who were also participants in this evaluation. A small handful of the other participants share similar visions in their product portfolios, but the 2019 MITRE evaluation did not include any of these non-endpoint or partner telemetry sources. Therefore, a key driver of differentiation that empowers security teams to understand product performance is not represented in the current visibility results. We look forward to a future where the evaluation continues to broaden its scope and include a wider variety of visibility sources and methods.
Guideline #2: Stay focused on the primary and most important evaluation criteria: visibility and detections.
As you become familiar with the evaluation, you will quickly find that it is primarily focused on visibility (telemetry) and detections (general, tactic, technique, and MSSP). These focus areas make the most sense from a security product value perspective. They are the most prominent in the attack execution and evaluation criteria, while linking directly into the MITRE ATT&CK framework from which the evaluation is based.
There are also secondary modifiers as part of the evaluation, which include categories such as host interrogation, alert creation, correlations, configuration changes, residual artifacts, and delayed processing. These are not as important as the core visibility and detection categories. While examining our own results, as well as those of other participants, we found in many cases that the secondary modifiers tend to be less well-defined and offer a wide spread of potential interpretations. We see a growing trend where the analysis being published actually skips the primary visibility and detection categories (likely due to performance issues on the primary tasks of visibility and detections) in favor of casting the secondary modifiers in advantageous ways. If you’re using the MITRE ATT&CK Evaluation results to inform your own decisions, don’t fall into the trap of pivoting to the modifiers as your primary insight for this evaluation.
Furthermore, technique detections are the most important part of the detection categories as they provide the most specific mapping to attacker behaviors. After all, the MITRE evaluation is based on the ATT&CK framework which is squarely focused on cataloging techniques at its most specific level. For example, Figure 2 shows the breakdown of automated detections with participants ordered by their technique detection volume. The top half of participants are grouped closely in their technique detection performance while their total automated detection levels, including general and tactic detections, are more diverse. In other words, if you were only looking at total detections you would lose the nuanced view of techniques which is provided by breaking down the detection types.

Figure 2: Breakdown of automated detections (general, tactic, technique), with participants ordered by total technique coverage. Metrics as shown are without allowing for configuration changes during the evaluation.
The 2019 MITRE Evaluation has no penalty for false positive detections. We believe the outcomes of the general detection category may be a related consequence. Many participants appear to have elevated telemetry directly as a general detection or alert which in practice would be a potentially noisy approach for security analysts. Alternatively, mapping a detection to a specific technique reveals a deliberate analysis and promotion of attacker behavior by the underlying analytic processing system. We follow this philosophy within Red Cloak TDR and MDR by mapping all of our detections and alerts to techniques. This is reflected in our own results in Figure 2 which shows strong technique coverage and little emphasis on tactic or general detections. Simply put, technique detections are higher quality compared to general detections.
We were surprised that some vendors had relatively poor performance on automated detections during the evaluation. In particular Scorpius and Taurus (both well-established players in the market) showed strong visibility coverage (Figure 1) but relatively low automated detection coverage (Figure 2). In relation there were some new, less well-established vendors who performed well on detections (kudos to them!). There are also interesting dynamics, such as Draco, which has low telemetry coverage (Figure 1) with a correspondingly high detection coverage (Figure 2), including a high amount of general detections. That dynamic hints at actions which likely took advantage of the lack of false positive penalties in the evaluation but may not be well-suited for deployment in practice.
We have also heard growing concerns on the MSSP detection category. In fact, MITRE has already removed the category from the future 2020 evaluation. However, the MSSP category is a legitimate detection category in the 2019 evaluation, particularly for participants who have managed services within their product portfolios. We understand firsthand that both standalone products and managed services have complimentary roles in the market - in fact, many of our customers rely on our expert security teams while working side-by-side in our software products every day. However, there are likely better methods for testing managed services as part of this evaluation. A closed book red team to test the skills and capability of the managed service team (as well as tracking time to detection and response, etc.) would be a potential improvement for future evaluations.
While our primary focus should remain on visibility and detections, you may find some insights from the secondary modifiers. We caution against drawing any broad conclusions on these secondary modifiers. In future evaluations, we would like to see improved clarity on exactly what is expected for each modifier, visibility and detection category. For example, the challenges of interpreting correlation capabilities or determining which specific visibility sources might count as a telemetry detection could be alleviated in the future with improved upfront published definitions or more detailed post-evaluation decision-making criteria in addition to the documentation MITRE provided to participants.
The configuration change modifier is an example of including some finer grained definition with its two sub-categories which can provide some interesting analysis. Figure 3 shows the breakdown of participants who made configuration changes (UX or detections) during the evaluation. While seven participants made no changes (including Secureworks), the rest predominantly made detection related configuration changes. As the evaluation is “open-book” describing the attacks, making detection configuration changes during the evaluation raises significant questions on whether it is a valid action compared to those who made no changes. Excluding configuration changes during analysis most accurately aligns to the spirit of a blind out-of-the-box configuration under test which most customers expect to experience.
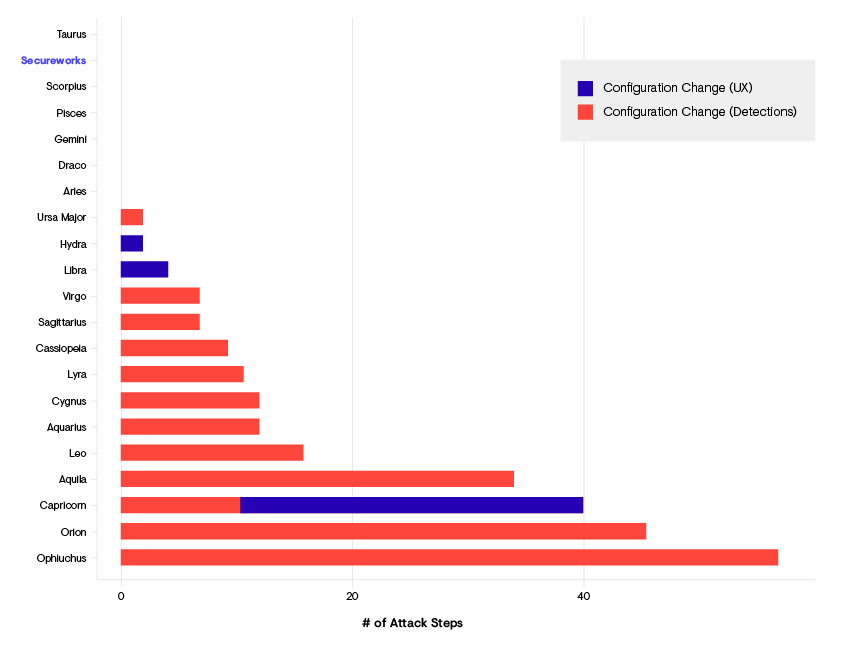
Figure 3: Breakdown of configuration changes made by participants (if any) and the number of attack sub-steps those configuration changes impacted.
Guideline #3: Keep in mind MITRE’s original evaluation intentions and goals. Focus on the techniques of most value to you.
MITRE explains their intention for hosting these evaluations in their public documentation, but it’s worth reiterating here:
- Empower end-users with objective insights into how to use specific commercial security products to detect known adversary behaviors.
- Provide transparency around the true capabilities of security products and services to detect known adversary behaviors.
- Drive the security vendor community to enhance their capability to detect known adversary behaviors.
These evaluations are not intended to be a traditional competition. There is not a declared winner, and there is no trophy to be won. MITRE provides no scores, rankings, or ratings. Instead, they show how each vendor approaches endpoint threat detection in the context of the ATT&CK framework. While there is a tendency to leverage the evaluation results to summarize a single salient point or basic recommendation for potential buyers, our first-hand experience showed us that the results require a nuance level that likely makes those objectives difficult to achieve. You can quickly determine which bottom performing products will likely not serve you well, but it’s challenging to determine which vendor product is best suited for your environment. MITRE recommends this guide, which includes a walkthrough of how to access the results, suggestions for key decision making factors that might help you select a product, and a method to execute your own version of this evaluation through an automated red team testing framework. Of course no generalized evaluation will ever directly indicate which product best matches your specific environment or security strategy, nor will it account for your security program maturity, or include tests for your particular environment.
Analyzing the techniques while exploring the evaluation results, however, will help tailor analysis while remaining true to MITRE’s evaluation intent. For example, consider Figure 4 which lays out a heatmap of telemetry coverage by executed attack technique. This view helps drill down into specifics for each product and highlights areas of strength or weakness. Keep in mind that each of the techniques are not on an equal footing from a severity standpoint. Security teams should take a risk-based approach by determining which techniques are most important to their environment and threat model. Ranking the priority order of the 57 techniques leveraged during the evaluation can be informed from historical IR engagements, research indications of malicious behavioral trends, or your own security team’s red team findings.
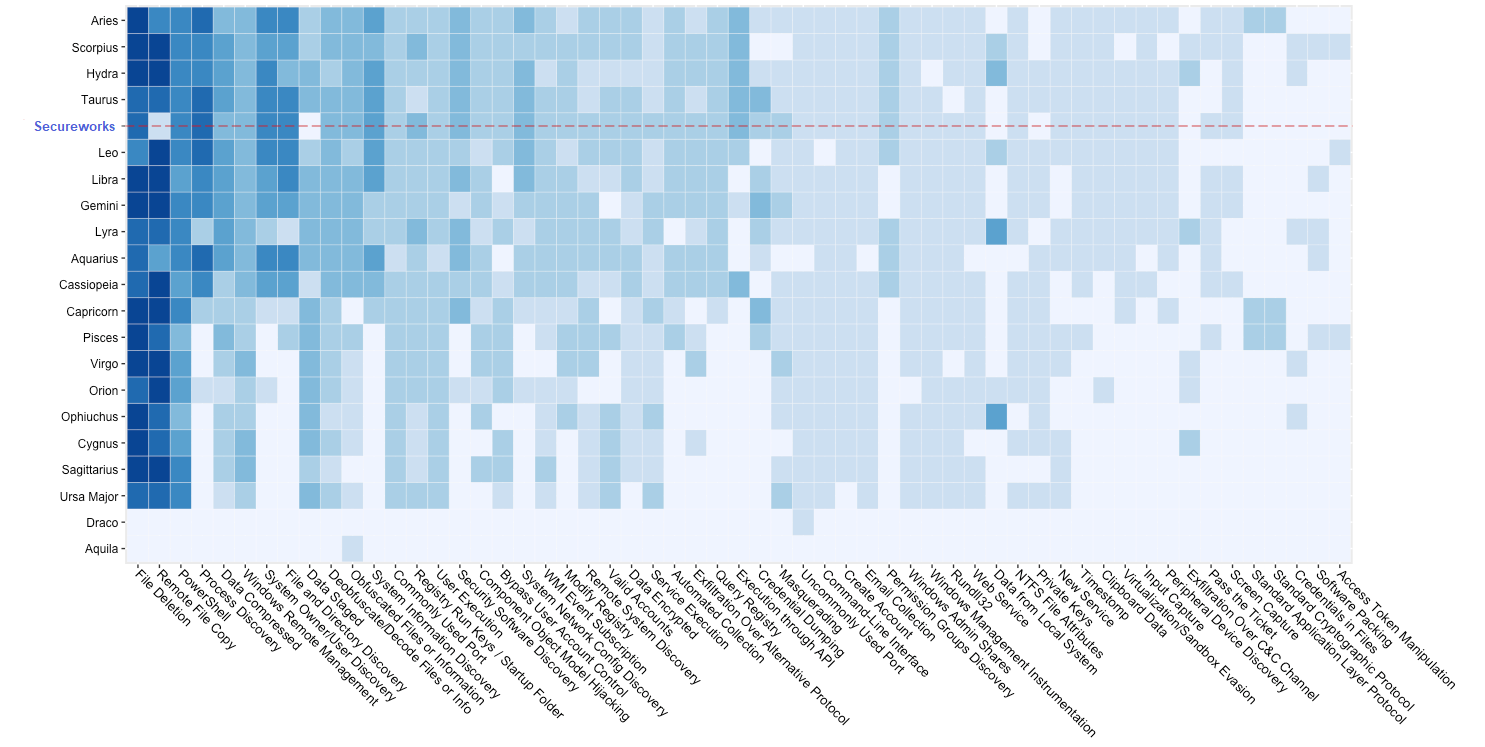
Figure 4: Heatmap of telemetry coverage broken out by observed attack technique. Darker squares indicate more telemetry coverage. The most commonly covered techniques run from left to right. The participants with the highest number of telemetry detections run from top to bottom. Metrics as shown are without allowing for configuration changes during the evaluation.
Recap
We hope our guidance and insights will inspire you to explore the 2019 MITRE evaluation results with renewed spirit. You will find optimistic indicators paired with challenges for determining meaningful product differences. Maximize the value of these results by focusing on visibility and detections, particularly by diving into the product details around technique coverage. When thinking about endpoint security products for your security program, there is a lot more to consider beyond the evaluation, but we are confident that there are meaningful insights to be uncovered from this latest round. Use any insights that you generate as a foundation for designing a holistic approach to your security posture through increased visibility and detection capabilities, not only on endpoints but also from network sensors, syslog sources, cloud service APIs, and more.
Secureworks has been acquired by Sophos. To view all new blogs, including those on threat intelligence from the Counter Threat Unit, visit: https://news.sophos.com/en-us/.