
With the recently disclosed hacking incident inside Google and other major companies, much of the world has begun to wake up to what the infosec community has known for some time there is a persistent campaign of "espionage-by-malware" emanating from the People's Republic of China (PRC). Corporate and state secrets both have been shanghaied over a period of five or more years, and the activity becomes bolder over time with little public acknowledgement or response from the U.S. government.
"Operation Aurora" is the latest in a series of attacks originating out of Mainland China. Previous attacks have been known as "GhostNet" and "Titan Rain." Operation Aurora takes its name directly from the hackers this time the name was coined after virus analysts found unique strings in some of the malware involved in the attack. These strings are debug symbol file paths in source code that has apparently been custom-written for these attacks. The paths were left behind in the compiled binaries as shown below:

Although the code behind Operation Aurora has only recently been discovered, and the known samples of the main backdoor trojan (called Hydraq by antivirus companies) appear to be no older than 2009. It appears that development of Aurora has been in the works for quite some time some of the custom modules in the Aurora codebase have compiler time stamps dating back to May 2006. This date is only a year or so after the Titan Rain attacks, which largely used widely-available trojans that were already known to antivirus companies. As a result of using completely original code and then only in highly-targeted attacks, the Aurora code seems to have escaped detection for quite some time.
The compiler often offers other clues to a malware sample's origin. For instance, if the binary uses a PE resource section, the resource's headers will often provide a language code. The Hydraq component does use a resource section, but in this case, the author was careful to either compile the code on an English-language system, or they edited the language code in the binary after-the-fact. So outside of the fact that PRC IP addresses have been used as control servers in the attacks, there is no "hard evidence" of involvement of the PRC or any agents thereof.
There is one interesting clue in the Hydraq binary that points back to mainland China, however. While analyzing the samples, I noticed a CRC (cyclic redundancy check) algorithm that seemed somewhat unusual. CRCs are used to check for errors that might have been introduced into stored or transferred data. There are many different CRC algorithms and implementations of those algorithms, but this is one I had not previously seen in any of my reverse-engineering efforts. Below is the raw assembly code for the CRC algorithm in Hydraq:

The first thing that is unusual about this CRC algorithm is the size of the table of constants (the incrementing values in the left pane of the assembly listing). Most 16 or 32-bit CRC algorithms use a hard-coded table of 256 constants. The CRC algorithm used in Hydraq uses a table of only 16 constants; basically a truncated version of the typical 256-value table. By decompiling the algorithm and searching the Internet for source code with similar constants, operations and a 16-value CRC table size, I was able to locate one instance of source code that fully matched the structural code implementation in Hydraq and also produced the same output when given the same input:

This source code was created to implement a 16-bit CRC algorithm compatible with the implementation known as "CRC-16 XMODEM", while requiring only a 16-value CRC table. It is actually a clever optimization of the standard CRC-16 reference code that allows the CRC-16 algorithm to be used in applications where memory is at a premium, such as hobby microcontrollers. Because the author used the C "int" type to store the CRC value, the number of bits in the output is dependent on the platform on which the code is compiled. In the case of Hydraq, which is a 32-bit Windows DLL, this CRC-16 implementation actually outputs a 32-bit value, which makes it compatible with neither existing CRC-16 nor CRC-32 implementations.
Perhaps the most interesting aspect of this source code sample is that it is of Chinese origin, released as part of a Chinese-language paper on optimizing CRC algorithms for use in microcontrollers. The full paper was published in simplified Chinese characters, and all existing references and publications of the sample source code seem to be exclusively on Chinese websites. This CRC-16 implementation seems to be virtually unknown outside of China, as shown by a Google search for one of the key variables, "crc_ta[16]". At the time of this writing, almost every page with meaningful content concerning the algorithm is Chinese:
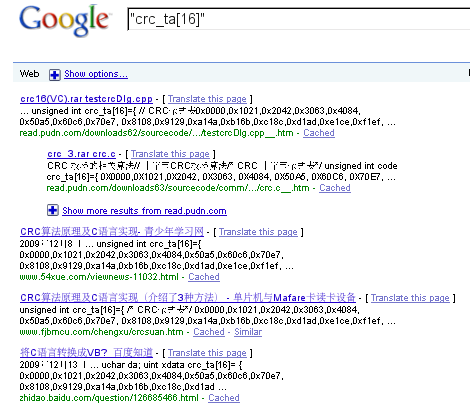
This information strongly indicates the Aurora codebase originated with someone who is comfortable reading simplified Chinese. Although source code itself is not restrained by any particular human language or nationality, most programmers reuse code documented in their native language. To do otherwise is to invite bugs and other unexpected problems that might arise from misunderstanding of the source code's purpose and implementation as given by the code comments or documentation.
In my opinion, the use of this unique CRC implementation in Hydraq is evidence that someone from within the PRC authored the Aurora codebase. And certainly, considering the scope, choice of targets and the overwhelming boldness of the attacks (in light of the harsh penalties we have seen handed out in communist China for other computer intrusion offenses), this creates speculation around whether the attacks could be state-sponsored.